

闲来偶然想起前天听领导提到其试用“大瓦特”模型预测电量,疑因内网无法检索关联历史统计数据无果,感觉这倒是个挺有创意的想法,遂随手测试了业界若干知名大模型,无意间也再次领略了所谓的“AI幻觉”,结果还是挺有趣,小结几点思考供诸君参考。
【不同通用大模型对简单提示语的反馈】
按照经验,对于“预测电量”这种相对复杂的需求,在通用大模型下直接用“请预测汕头市澄海区2025年用电量的增长率”之类的简单提示语,效果一般不尽人意,比如通义千问,啰嗦一大堆后跟你讲“确切的数值无法准确给出”。
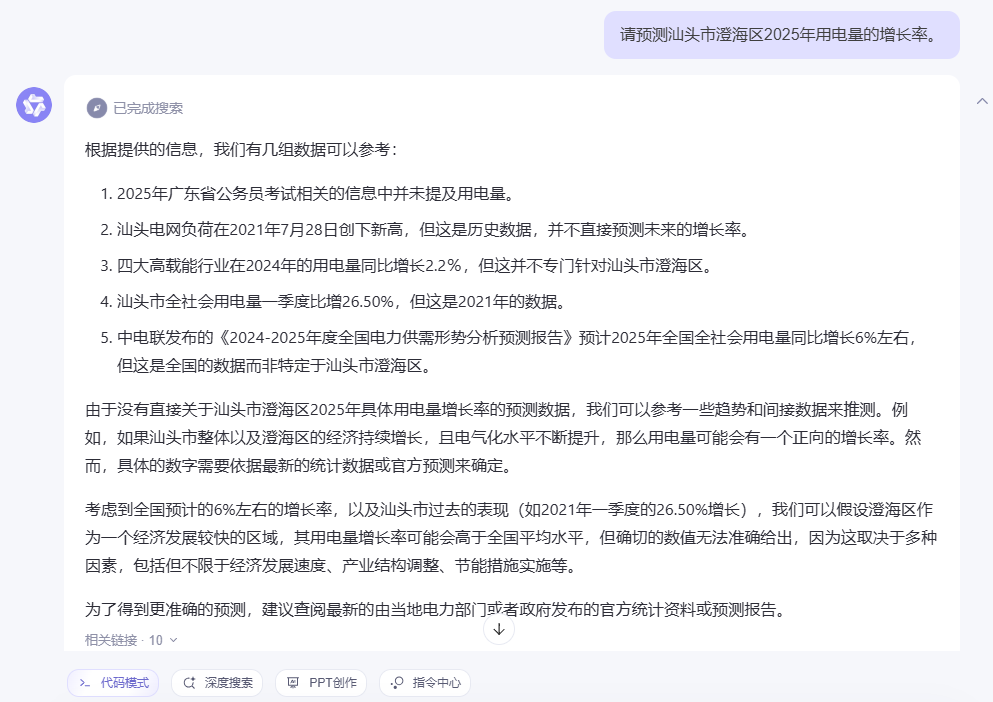
即便是在疑似推理大模型的“深度搜索”模式下,虽然能基于地理位置相近且发展模式相似,用潮州的数据做了类比,但给出的6%-9%的预测区间依然十分粗糙。
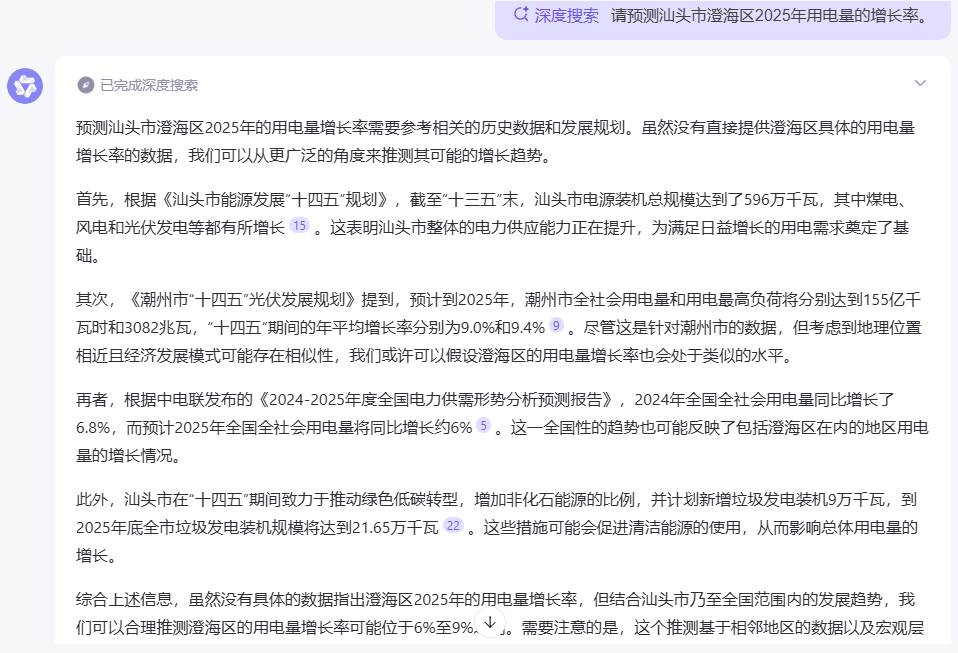
相对而言,Kimi爬取信息的能力似乎更强,但给出7%-9%这一预测区间的过程显得非常主观,有兴趣的同志可以进一步核实一下它有没胡说八道。

DeepSeek的效果相对亮眼,给出的预测过程更趋客观,甚至提出可以使用时间序列分析、回归分析等统计方法进行综合预测,并最终给出了4%-6%的预测空间。

单就这一次测试而言,各个大模型的靠谱程度的确存在一定的差异。当然,Deepseek给出的这个结果是否可信还有很大的考量空间。大家应该也都反复听说过“AI幻觉”这个概念,大模型编造它认为真实存在的信息而人类还感觉合理可信这一现象自大模型诞生之日起就存在,因此我们不能止步于此。
【提示语优化策略的应用】
采取“赋予角色、限定领域”+“分步提问”的方式改进提示语,赋予通义千问“数据统计师”角色,并限定“电力行业”——个人理解,这种处理方式能第一时间引导AI聚焦特定领域的知识,提高检索效率,特别是在服务响应资源有限、响应体验要求较高的情况下,能在很大程度上优化生成内容的质量。
近期也看到一些观点认为推理大模型本身具备很强的逻辑能力,提问时明确角色、领域反而可能误导大模型,影响生成内容的质量——这个观点见仁见智,个人认为,只要我们明确的角色、领域是完全正确的,依然能帮助大模型提高效率。换句话说,AI生成内容的质量,和使用者提问的能力密不可分。不管怎样,我们大部分人接触的还是通用大模型,掌握该技巧十分必要。
在此基础上分步提问,避开直接让AI“预测电量”的误区,先让AI“分析一下影响一个地区用电量的主要因素”,将人工智能思考的方向控制在自己手上,更好地保障人机协同。
显然,经过提示语优化,原先表现相对差劲的通义千问也能客观性、体系化地输出系列内容。

基于AI输出的内容,继续分步提出需求:请以汕头市澄海区为例,分析一下过去若干年,上述因素对每年用电量的影响。

能够看出,通义千问认识的澄海的确是我希望它分析的澄海,核实这一点对于避免后续预测过程中出现的张冠李戴十分必要。到此本可以切入正题“未来几年澄海区的用电趋势会如何?”
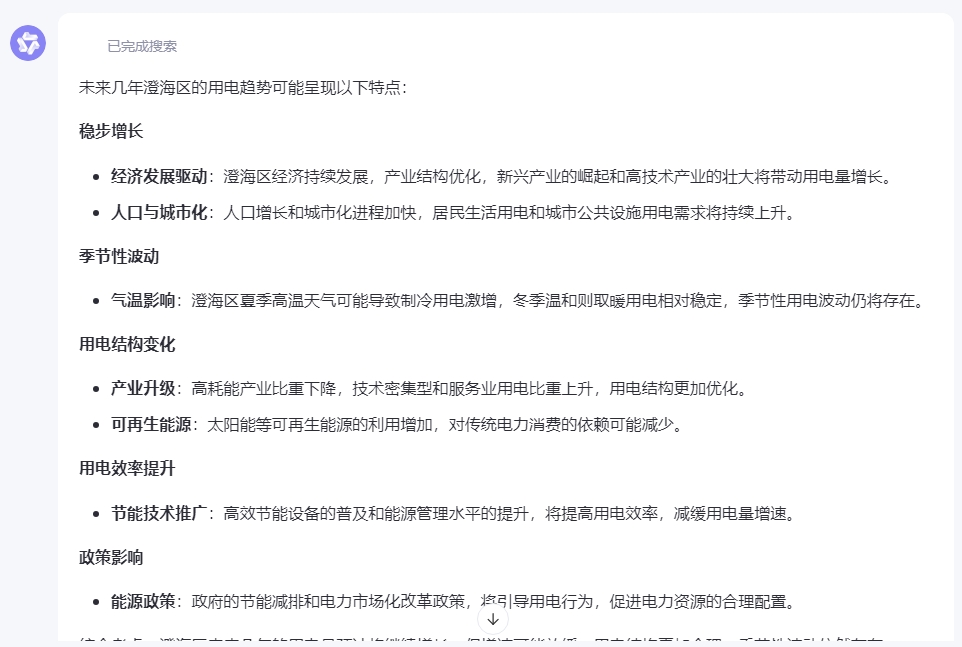
可惜AI输出的全是非量化的预判,我们必须进一步明确需求“请基于以上分析,预测2025年澄海区用电量的增长率,并说明预测的依据”。
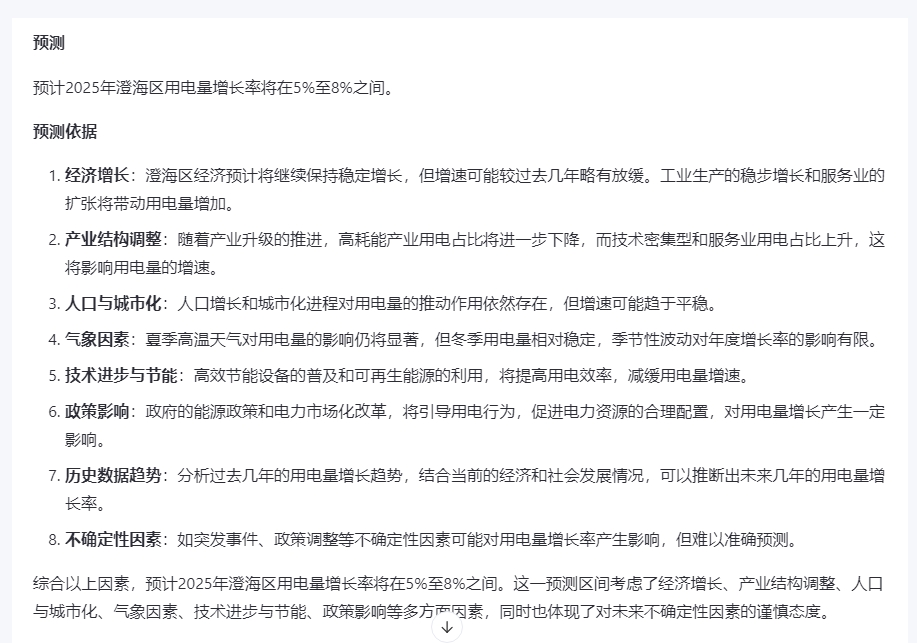
可以看到AI虽然给出了5%-8%的预测区间,但并未说明预测过程中具体用了何种方式、哪些数据。必须进一步质询“请详细说明5%至8%的预测值是如何计算出来的”。
然而AI输出的结果依然十分空泛,我们换个方式进一步质询“请详细说明5%至8%的预测值是基于什么样的模型预测出来的,模型输入的参数有哪些,具体参数值是多少。”

到此,问题的探讨已相对深入,但我们不难发现AI提到的模型输入参数用了很多“假设”的表述,这可能会在很大程度上影响电量增长预测的准确性。
而且随着上下文数量的增多和问题的深入,内容生成的速度会显著下降,在第6、7轮对话的时候甚至已经降到了1秒钟1个字符输出的龟速,大概率是服务器的资源做了限制,由此可见对于相对高的应用需求,本地部署一个大模型十分必要。
【遭遇AI幻觉】
进一步与AI核实确认,要求罗列出参数估计过程中使用的历史数据类别及其具体值,得到了一系列数据值及其来源说明。
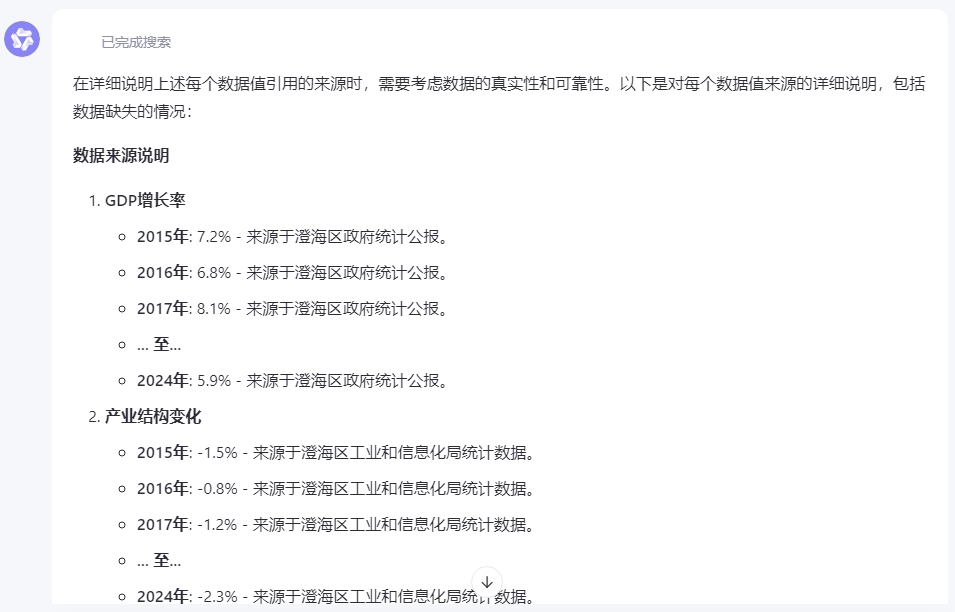
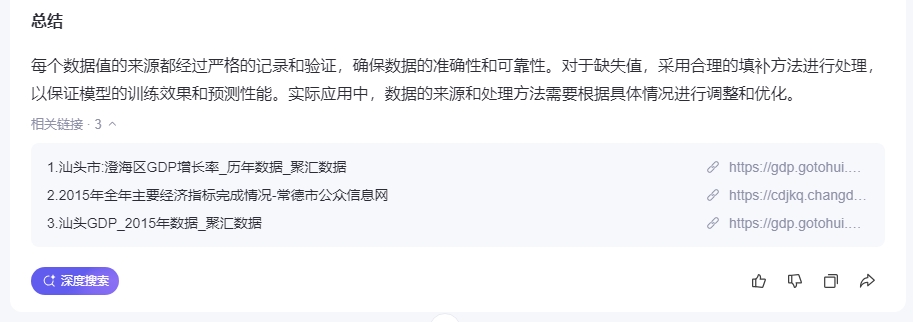
偶然间点击输出内容底部“相关链接”第二条时,发现莫名其妙引用了常德的数据。多了个心眼,遂手动检索了澄海区政府网站的统计月报,发现AI提到的2024年GDP增长率5.9%与政府公开数据4.5%显然不符。
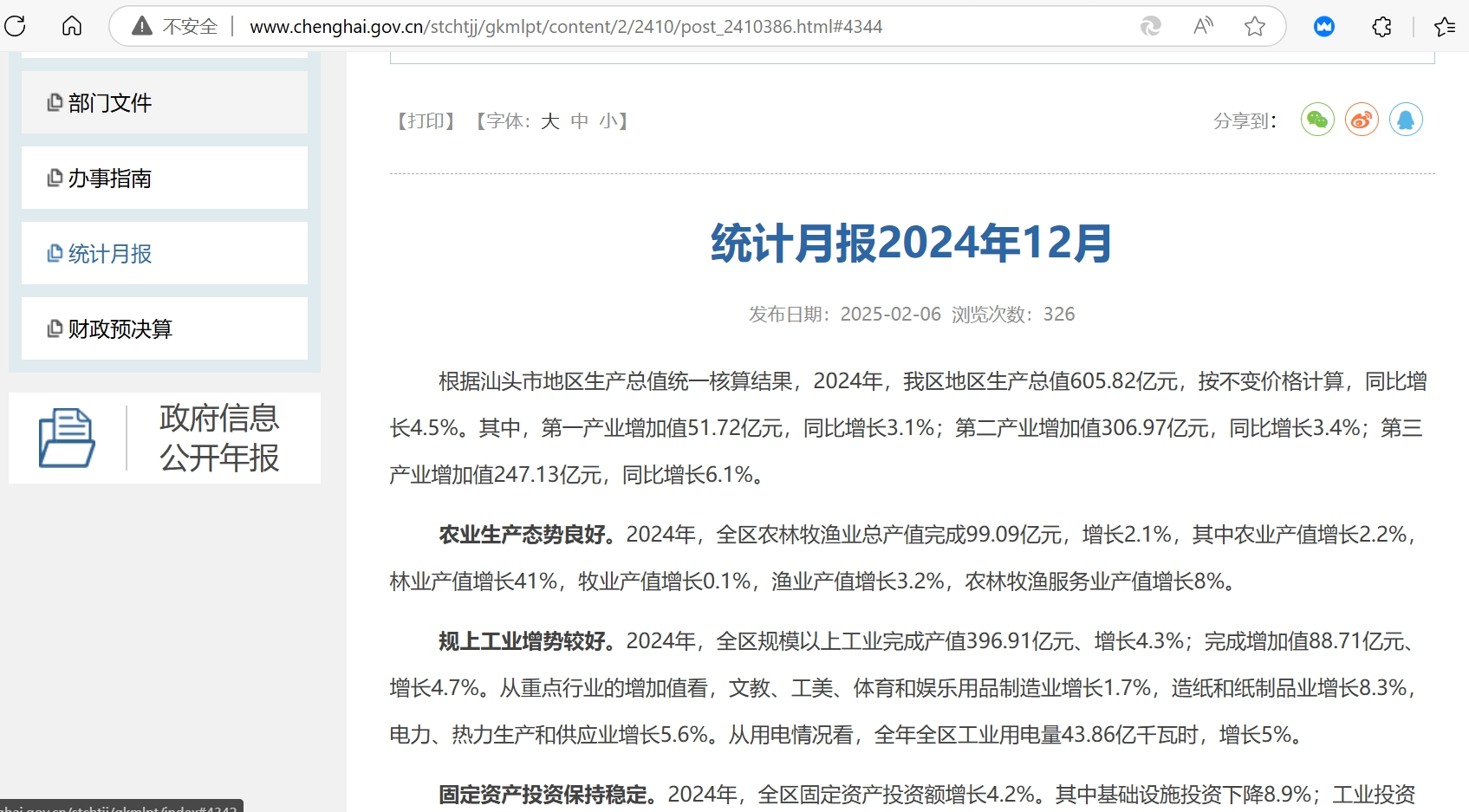
于是向AI质疑引用数据的准确性,并要求全面核查更正数据,重新预测。
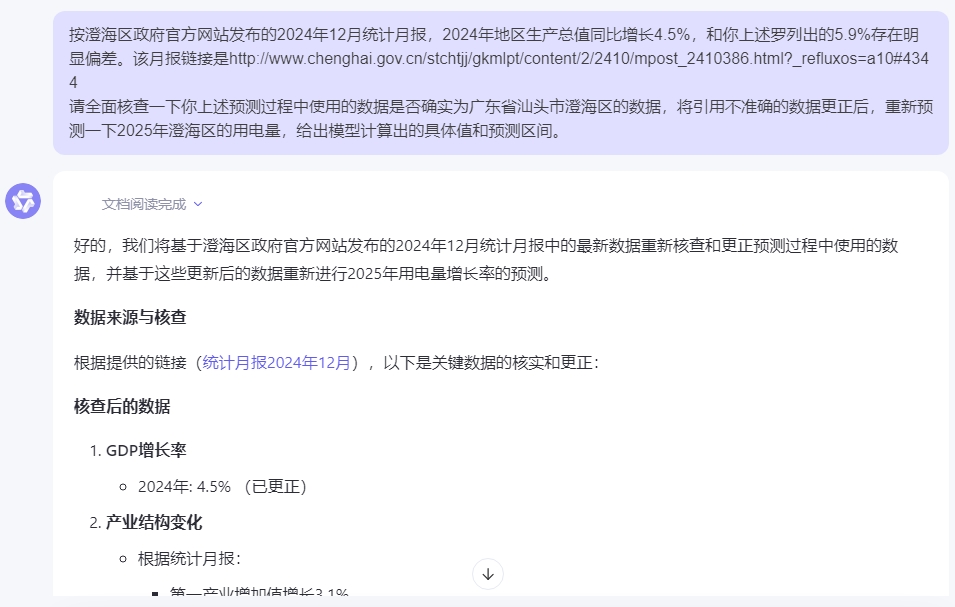
到此,通义千问开始化身“人工智障”,始终无法一次性爬取澄海区政府官网的相关数据并全面修正预测模型的输入,经过多番的曲解和反复的校正,最终计算出来5.64%的具体数据并给出了5%-6%的预测区间。
当然,这个结果在多大程度上可信依然值得商榷。令人后怕的是,假如过程中我没有点开附带链接发现引用的数据可能有问题、没有手动去检索官方数据核实AI提供的信息,而是迷信AI提供的有数据、有公式的貌似很科学可靠的“幻觉”,那么得到的结果可能离实际将有更大的差距。
【几点思考】
其一,过去的高等教育和社会经历让我们习惯了用百度等搜索引擎寻求答案——这在过去很长一段时间内极大提高了我们的效率,但相对人工智能生成内容,搜索引擎检索的方式已变得十分低效,也必将成为历史,需要我们有意识地改变习惯,才能重新与时代接轨。
其二,AI生成的内容,不宜囫囵吞枣、得之即用,必须要有批判的思想、保持怀疑的心态,多提几个是什么、为什么,尽量求证生成内容依据的来源,避免“AI幻觉”误事。
其三,AI生成内容并没有想象中难、也没有传说中简单,生成内容的质量极大依赖于提出需求的质量。基于此,学会与AI沟通的技巧十分必要——假以时日,AI可能真会淘汰一些人,但必然只会淘汰那些不擅长与AI沟通并获得支持的人。