我看见,玻璃洒满地
我看见,玻璃洒满地
这是一个骗局
冬春交替
却热得不合常理
我看见,
玻璃洒满地
满地是玻璃
他们本该属于一体
他们本该在一起
外力,
残酷的外力
使他们肢离解体
没有人问为什么
不会有人问为什么
作恶的人早已离去
留下,
一地的,
碎玻璃……
昨日往教室上课,路经天桥,见一地纯生啤酒碎玻璃,大学校园竟有此景,搞笑。不觉兴起,一路推敲,至一栋,此不伦不类之诗歌底稿打成,索性写到了记事本上。今日见记事本,又兴起,发到了这里。哈哈……

我看见,玻璃洒满地
这是一个骗局
冬春交替
却热得不合常理
我看见,
玻璃洒满地
满地是玻璃
他们本该属于一体
他们本该在一起
外力,
残酷的外力
使他们肢离解体
没有人问为什么
不会有人问为什么
作恶的人早已离去
留下,
一地的,
碎玻璃……
昨日往教室上课,路经天桥,见一地纯生啤酒碎玻璃,大学校园竟有此景,搞笑。不觉兴起,一路推敲,至一栋,此不伦不类之诗歌底稿打成,索性写到了记事本上。今日见记事本,又兴起,发到了这里。哈哈……
人生来就是一个矛盾体。
其一,欲望是永无止境的;
其二,惰性是无可避免的。
于是,一方面,欲望驱使你不断追求,不断超越……力图攀上人生的巅峰。另一方面,惰性却总是使你迟钝下来,只图安逸,不思进取。
成功者摆脱了惰性,在欲望的驱使下,成功了;失败者惰性过强,把欲望给抑制了,所以失败了。
然而,不管成功者与失败者,归结起来都应该属于失常者,因为他们没有把握大自然的规律,他们只是掌握了矛盾体的一个方面,而丢失了矛盾体的另外一个方面。换句简单点的话说——失调了。失调的结果是可怕的,内心会有无名的空洞感,空洞感使人不知所措,找不到继续生存的意义。所以成功者和失败者往往是不快乐的。
真正正常的人既有欲望,又有惰性,两者在动态中达到了天性的平衡。
这种人有目标,有追求,却又懂得放纵,敢于放纵。欲望和惰性在他们的身上达到了最美的协调。
所以,腾说:做一个快乐的人,不必过于计较得失,不必太过责备自己的堕落与不思进取。假如有某些事情你突然觉得很想得到它,那么,不必太过顾忌,追求吧,不要想:我能得到吗?要是得不到怎么办?没试过怎么知道得不到呢?!没试过怎么知道得得到呢?!
阳光
我舀了一杯暖暖的阳光
在凛冽的冬晨
不一小心洒在你的身上
你用纸巾擦干这缕阳光
不让一丝温暖
淌入你那冰封的心房
请不要做出:这首诗是抄来的……这样的假设。
写这首诗的过程是这样的:今天正午,由图书馆经天桥返楠园吃饭,其时阳光正暖,洒在身上甚觉恰意。于是一不小心热血沸腾,有了作诗的冲动,于是一不小心想到了“我舀了一杯暖暖的阳光”这个句子——虽然到现在还在郁闷为什么当初会想到了一杯阳光而不是一盆阳光一筐阳光呢?!——思考无果,只能将就给个答案:大概是因为当初饿昏了吧。接下来就简单多了,事实上最先想到的不是“在凛冽的冬晨,一不小心洒在你的身上”而是“在凛冽的冬晨,全部倒在你的身上”,后来想想这么写貌似有点不怀好意,当然,作为一个诗人,心怀好意是必须的,所以改成了现在的句子……在楠园饭饱之后,拿出纸巾插嘴,灵感突至,便有了“你用纸巾擦干这缕阳光”的说法,事实上就写诗而言,我应该改成“你用手帕擦干这缕阳光”,转念一想,都什么年代了,还手帕,遂不改。当然,擦干阳光干啥?!水到渠成,就有了后面的两句。
这就是现代诗……
当然,或许按照9年义务教育和3年高中教育语文课上学来的经验,你可以假设这首富有现代气息的诗歌描述了一个青年人对一个异性深有好感,于是决定冒险尝试接近——献殷勤——拿着一杯阳光假装不小心洒到那人的身上——好像这种做法是有点老套——不管了……庶知对方是个冷美人或酷男子,不鸟作者,于是乎作者哀伤不已,带着淡淡的不解和苦闷,遂有此诗。
当然,假如我告诉你这首诗的作者生活在水深火热的解放战争时期,那么按照惯例,我们可以得到这样的结论:作者是一个很乐观向上的人,虽然身处战乱的寒冬,仍对生命不离不弃,热情讴歌阳光。这时候,“你”就不是暗恋的异性了,应该理解为“残忍而冷漠的独裁统治者”,作者不惧强权,试图用自己的行动去感化独裁者,所以假装不小心把阳光洒到了独裁者身上,谁知独裁者冷酷依旧,把那阳光擦掉了,所以结果是:没结果……
这就是语文……
这几天着手做师大青年的新站点,原本定下是MySQL配Navicat Lite数据库管理软件——事实上Navicat Lite的确是个好东西,用户界面设计得很像SQL Server Management Studio Express,对于熟悉mssql的用户来说无疑很上手。更重要的是有免费版本,这对我们穷人来说是件大好事。
然而后来师兄又说navicat的免费版不靠谱,不能备份数据库——这就悲剧了,没人敢保证自己的数据库不会出错,不备份一出错就没救了,看来还是不得不用回phpmyadmin。
既然如此,也只好勉为其难配phpmyadmin了——记得大一的时候配过一次,过程相当痛苦,真可谓记忆犹新。
上官网找到了最新稳定版本phpMyAdmin3.3.8.1,毫不犹豫download了一个phpMyAdmin-3.3.8.1-all-languages.zip,虽然size比起其他压缩格式大了点,但.zip格式总让我更加放心,这只能说是一个癖好吧。
下完解压才想起,phpmyadmin必须在php环境下运行,由于到目前为止都没空去碰php,我的笔记本上也一直没有安装php的环境,这次看来不得不装了。于是乎上php官网windows下载区。发现最新版本是PHP 5.3 (5.3.4),仔细看了一下,有VC9、VC6、Non Thread Safe(非线性安全)、Thread Safe(线性安全)的区别,Google了一下,原来VC6版本是使用Visual Studio 6编译器编译的,如果PHP是用Apache来架设的,应该选择VC6版本;而VC9版本是使用Visual Studio 2008编译器编译的,如果PHP是用IIS来架设的,就选择VC9版本。而Thread Safe是线程安全,执行时会进行线程(Thread)安全检查,以防止有新要求就启动新线程的CGI执行方式而耗尽系统资源;Non Thread Safe是非线程安全,在执行时不进行线程(Thread)安全检查。官网不建议使用非线程安全版,于是下了一个线程安全的php-5.3.4-Win32-VC9-x86.msi。
由于我的系统是win7,win7的iis版本为iis 7,得师兄一篇博文(点这里看看)指导,知道有一个叫IIS Manager For IIS 7的图形化PHP管理软件,安装后可以在Internet 信息服务(IIS)管理器里找到一个PHP Manager的图标,方便对php进行各种设置。依照我热衷偷懒的本性,当然得装,于是屁颠屁颠得上 codeplex.com下载安装了一个。
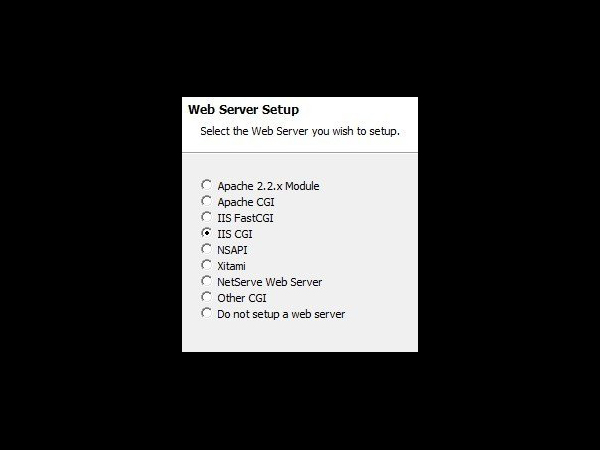
接下来安装php:中间提示要选择Web Server Setup,才发现我IIS CGI还没安装,于是打开控制面板——安装或关闭windows功能——Internet信息服务——万维网服务——应用程序开发功能——勾选CGI,确定安装。安装完毕继续安装php,当然Web Server Setup就选IIS CGI。
搞定php,着手配置phpmyadmin,为了方便管理,特意在信息服务器上新建了一个本地站点,把phpmyadmin解压到了这个站点的根目录下,又Google了一番,得到大致配置如下:
打开 libraries 目录下的 config.default.php 文件,依次找到下面各项,按照说明配置即可。
1、访问网址
$cfg['PmaAbsoluteUri'] = ''; //这里填写phpMyAdmin的访问网址
2、MySQL 主机信息
$cfg['Servers'][$i]['host'] = 'localhost'; //MySQL hostname or IP address 填写localhost或MySQL所在服务器的ip地址,如果MySQL和该phpMyAdmin在同一服务器,则按默认localhost
$cfg['Servers'][$i]['port'] = ''; //MySQL port - leave blank for default port 这是MySQL端口,默认为3306,保留为空即可,如果您安装MySQL时使用了其它的端口,需要在这里填写。
3、MySQL 用户名和密码
$cfg['Servers'][$i]['user'] = 'root'; //填写MySQL访问phpMyAdmin使用的MySQL用户名,默认为root
fg['Servers'][$i]['password'] = ''; //填写对应上述MySQL用户名的密码
4、认证方法
$cfg['Servers'][$i]['auth_type'] = 'cookie'; //考虑到安全的因素,建议这里填写cookie
在此有四种模式可供选择,cookie,http,HTTP,config:
config方式即输入phpMyAdmin的访问网址即可直接进入,无需输入用户名和密码,是不安全的,不推荐使用。
当该项设置为cookie,http或HTTP时,登录phpMyAdmin需要数据用户名和密码进行验证,具体如下:
PHP安装模式为Apache,可以使用http和cookie;
PHP安装模式为CGI,可以使用cookie。
5、短语密码(blowfish_secret)的设置
$cfg['blowfish_secret'] = '';
如果认证方法设置为cookie,就需要设置短语密码,设置为什么密码,由您自己决定,这里不能留空,否则会在登录phpMyAdmin时提示错误。
整个过程历时3、4个多小时,为了使用phpmyadmin,先后安装了php、IIS Manager For IIS 7、IIS CGI,可见这个世界的确是普遍联系的,牵一发而动全身,用在这里也不为过了。
在两种情况下,我们会心生恐惧:
其一,对身边的环境一无所知,无法断定前路凶险,不敢肯定自己能安然度过,于是心生恐惧——这是对未知的恐惧。
其二,对身边的环境了解透彻,知道在这种情况下凶险万分,自己断定必然无法安然度过,于是心生恐惧——这是对已知的恐惧。
然而,不论是已知的恐惧抑或未知的恐惧,归根到底,恐惧都是源于对自身实力的不信任,对自己产生了怀疑,自己否定自己,所谓“魔由心生”,说得正是此理。
哀莫大于心死,假如连自己都不信任自己的能力,不相信自己有实力战胜眼前的困难,不知不觉中,自己已经把困难放大了一百倍。试问,抱着必定失败的心态,还能指望成功么?!造化偶尔弄人,但概率却从未出错过。
勇者无惧,并非勇者在这世界上没有什么恐惧,而是勇者用一颗勇敢的心,对自己的能力相当自信,于是也就无所畏惧了……
恐惧啊,你这垃圾……
校道上,一女生问曰:你对三国熟不熟?
另一女生答曰:不很熟,玩“三国杀”熟的…
这真不知道该算是悲剧还是喜剧。一个大学生,说得不客气点还是所谓的一本重点、广东名牌、211工程的学生,对三国的了解,不是通过史书,不是通过古典名著,竟然是通过一副纸牌,这到底是社会的一种进步还是倒退?!
我很讨厌“文化缺失”这种说法,但今天似乎除了用这个词,找不到更合适的了……
这阵子跟着老师和一班兄弟搞数据挖掘,一心想找个实用的系统案例分析一下,以便对今后所期望开发出来的应用系统有个大概的把握。傍晚洗澡时突来灵感,想起了坐车网(www.zuoche.com),这的确是一个数据挖掘大显神通的好舞台,起码我这么认为。
就我菜鸟级的见解,数据挖掘这种技术主要针对的是海量数据——从海量数据中抽象出一个模型,根据输入的参数,模型经过分析得到一个期望的输出。而“坐车网”,显而易见,需要包涵全国各地的每条公交线路信息、每条公交线路上的每个站点信息,如此数据量,够得上海量了。“坐车网”的主要功能就是在B/S架构下,用户通过提交一份表单(用户必须输入的信息很简单:出发地、目的地,仅此而已,当然,如果你喜欢的话还可以进行一些高级设置,比如期望搜索到白天还是夜里的公交线路),服务器通过get方式获得用户输入参数(之所以如此肯定为get方式,请看下面解释),通过某种未知的手段(实话实说,迄今为止我还没有确切的证据证明是通过什么手段实现的,话说回来,假如我知道了,那还得了,哈哈),返回由出发地到达目的地的各种交通线路转乘方式。
打开 www.zuoche.com 随便输入一个出发地和一个目的地,可以看到浏览器的地址栏上出现了这么一个URL:
“http://www.zuoche.com/traffic/?si=00c4538e_2369515150&di=2708569b_3584974491&time=1&stgy=0&peop=0&c1=%E4%B8%8A%E6%B5%B7&c2=%E4%B8%9C%E8%8E%9E&x=40&y=9”,
再点击“返回首页”的超链接,发现URL为“http://www.zuoche.com/traffic/index.jspx”。由第二个URL后面的index.jspx可以得知这个网站用的是java web快速开发框架,本质上是java。对于第一个UTL,http://www.zuoche.com/traffic/ 部分是域名,“?”后面跟着的很长一串东西就是所谓的传递参数,这也是上面断定get方式的依据,其中“si”应该是出发地,“di”是目的地,“time”自然是时间,“time=1”表示的是白天,假如选择夜车的话“time=2”;“stgy=0&peop=0”应该分别对应“尽量少走路和尽量少乘车”“C1、C2”是出发地和目的地的城市,比如广州,对应“%E5%B9%BF%E5%B7%9E”。
上述是网站的功能实现,很简单,给用户一个傻瓜式的界面,让用户输入参数,当用户点击查询时,浏览器把参数传回给服务器,服务器经过一系列的功能实现后把线路信息返还回来,在浏览器上呈现给浏览者。
下面是重点了,我要对比一下在非“数据挖掘”思想指导下的功能实现和“数据挖掘”思想指导下的实现优劣。当然,由于本人初学数据挖掘,不免有很多认识误区,高手发现了,还望不吝赐教。
先说说完全不用数据挖掘思想实现线路的查询:
我想到的是首先应该把某个城市,比如广州的各个公众比较熟悉的地名还有标志性的建筑所在地点的经度纬度和地名对应起来存储在数据库中。
然后建一张名为station的表,key为station,就是每个公交或者地铁站点(未免混乱,地铁就权当公交算了,事实上实现起来应该是一致的),这个表还应有一个字段“place”,用来存放在每个站点下车后步行能够到达的地点,还必须有一个字段“path”用来存储每个站点上经过的公交线路。
再建一张“path”表,用来存放每条线路经过的站点。key为path,即线路,用一个字段station存储线路上的每个站点名。
当用户输入出发地和目的地时,首先要在一堆混乱的地名中查找到离出发地和目的地所在位置最近的车站名称,这个过程的时间复杂度是难以估量的,假如运气不好的话或许要遍历整个城市公交站点组成的数据表,发生这种情况只能说:悲剧。当然,采用地域分区和地点索引的方式能显著提高检索的效率,做法是存储地点的经纬信息时先依照一定的规则(人为划区或者是地域划区都可以)把地点信息存放到不同的数据单元中,当用户输入查询参数时要求用户同时输入出发地和目的地的大致所在分区(这种情况下选用下拉选单或单项按钮,用户体验会更好),这样做可以把需要检索的数据范围大大缩小。
找到离出发地和目的地最近的站点A和B后,以出发地站点A为参数,在station表中查找经过这个站点的所有公交路线,以这些路线为参数,在path表中查找B站点,同理,如果运气好的话,刚好A和B在同一条线路上,这时能很快的返回线路信息;假如所有线路都无法搜到站点B,则必须以每条线路上经过的站点为参数再在station表中搜索此站点对应的线路,再以这些线路为参数在path表中搜索这些线路是否经过B站点……如此循环往复,总有一个机会能查询到B站点,这时需要根据记录下来的线路信息依次排好,统计出中间需要经过的站点数和转乘的次数,再用一个函数算出出发地到A站点,目的地到B站点的大概距离(还记得我们存了所有地名的经纬度吗?这时派上用场了),当然,这个距离是相当大概的,因为用经纬度算出来的距离只能是直线的,假如出发地与A点间有建筑物挡住的话,那就不得不用曲线绕过了,这时算出来的距离就只能说是很大概的。
由上面的过程不难发现,站点B在第一、二步搜索中,搜索的复杂度是比较低的,假如在这前几步搜索中没能找到B,那后面的搜索量几乎是以指数级增大的。众所周知,查询数据库本身就是一件很耗费资源的事,当有大量数据需要查询时,困难程度无法想象。
所以非数据挖掘的这种线路查询系统虽说有实现的可能,但是在现实中估计不会有人那么无聊去开发,即使开发出来,最多也只能用在很小的局部地区,城市越大,平均需要的搜索时间将越长。这时很不实用的。
所以我们不得不采用数据挖掘的思想来解决这个问题。
我们要做的是训练出一个神经网络,这个网络的功能是可以根据输入的出发地和目的地智能地提供中间的线路换乘信息。
要训练这么一个神经网络我想到的解决方案是:把全市所有的公交线路以某种特定的方式(矩阵也好、指针也罢)存储起来,使所有公交线路形成一个网状的数据结构。建立一个模型,给其权赋一个任意初值,使用出发地、目的地、中间线路这样的参数对不断去改变测验模型,修改其权值……最后得到的一个模型将是最接近于我们需要的智能模型。
当然,真正实现起来或许没这么简单,但思路应该大抵如此。
注意到坐车网查询出来的坐车方式中一般还有一条出租车的方式,比如:乘坐出租车,共行驶19.2公里,费用约55元。这个用数据挖掘实现起来还是比较有保证的,方法是收集尽可能多的出租车发票作为模型的训练参数。假如不训练出一个模型的话,能做的估计也就是依据两个地点的经纬度用算法算出两点间的距离——可见这个距离是相当不具有参考性的,因为世界上的道路不总是直来直去的。
通过以上对比,不难看出采用数据挖掘的方式的确可以提高工作效率,在信息高度膨胀的今天,掌握效率无疑掌握了经济的咽喉,所以不难推测,这种技术在未来若干年内还是有发展前景的,诸君算是找对门路了。奋斗吧!!哈哈……
当所谓的非主流渐渐主流时,
有人惊呼:这个世界还有常理可言吗?
但我知道常理还是有的,
因为变成主流的非主流终将会慢慢地再度非主流,
取代它的,
将是另外一种非主流,
这就是常理……
不要在我辉煌或者困顿的时候对我的前程做出任何预测或断言,
因为当我一败涂地或者东山再起时,
你们会发觉自己当初的预言是多么得无知与可笑!
这几天和本部一个兄弟夏先生合作完成华师大的亚运志愿者网站。由于说好我负责ASP部分,所以拿到本部发来的页面后只是顺手用360安全浏览器看了一下,毫无疑问,页面设计得很漂亮,这充分说明我们的分工是正确的——起码对于美工来说,夏先生比我好。
没有过多考虑,匆匆忙忙开始拷代码,花了一天多的时间,期间与本部进行了n次的交流,基本完成了页面功能。并上传到了服务器。心里还一个劲地感慨:合作的力量还真是强大啊。因为之前总是一个人做整个网站,基本上都得拖几个星期,就页面的设计已经能累死人了。现在有个人帮忙写css,效果的确不错。这充分说明,独行侠的年代已经过时了。当然,剩下的事可以说不是我的事了,我可不想无聊到做上传文章之类的事。
没想到的是昨晚同是亚运网络小组的梁兄突然说网站有问题,看了一下,原来用的是腾讯的TT浏览器。这才突然想起做完整个页面后都没有在各个浏览器上做过相关测试。事实上我的电脑上并没安装TT,这是个很大的漏洞,因为腾讯的爪牙现在几乎是伸遍了中国任何一台能上网的PC,TT浏览器使用量还是相当可观的,而我之前测试页面居然一直没有留意到真是吓了一跳。忙回来下了一个安装。事实证明,页面在TT上确实是存在问题的。有这么几个div的嵌套:
<div>
<div style="float:left;">框一</div>
<div style="float:left;">框二</div>
</div>
在IE8上,呈现出来的页面是理想的:框一在框二的左边。但在TT上,框二却掉到了框一的下面。原本以为又是浏览器不兼容的问题,决定用css hack解决。Google了一番,却发现到此都说TT使用的是IE的核心,因而只要页面在IE上显示正常,在TT上也应该是正常的,所以TT没有特定的css hack可写。这真是见鬼了,因为在我的电脑上,整个页面在IE(win7的IE版本是IE8)上是很正常的,照上面的理论,TT上也应该正常才是。怀着不服气的心理检查了半天的css,发现没有任何问题,情绪无比低落。就在准备投降的时候,突然灵感光顾,顺手打开了IETester,先用IE6试验,发现整个页面几乎都是变形的,面红耳赤地赶紧关掉,幸好这些问题可以用css hack解决,算不上问题,又顺手用IE7试验了一下,瞬时气不打一处来。这个页面在ie7下的bug和TT上的错误是完全一致的。这么说来,TT使用的内核应该是ie7的内核,而不是我系统上的ie8的内核,这到底是什么原因,有待了解。但既然是ie7的内核,问题就好解决多了,起码我可以使用ie7的css hack来处理,这比起无从下手要简单N倍了。
记得韩寒有句很经典的话:灵感就像公共汽车,不来的时候一部都没有,一来的时候几部一起来。此时我突然又想起应该在TT上查看一下页面的源代码,起码能知道asp输出的html是不是有问题的。检查之后,发现了一个很重要的线索:如上所述的两个div,放的都是用asp生成的一个标题列表,这些列表是用table包围起来的,如下:
<div class="pack">
<div style="float:left;" id="div1">
<table><tr><td style="width:100%">XX的标题</td></tr></table>
</div>
<div style="float:left;" id="div2">
<table><tr><td style="width:100%">XX的标题</td></tr></table>
</div>
</div>
问题出在width:100%上,重复检查了一下css,发现夏兄没给div1和div2定义width,而我写asp的时候,却给td输出了一个wdith=100%的属性,所以div1就把整个pack的width占据了,div2自然只好放到了下面。明白了道理,解决起来就简单得不得了了,只要给div1和div2加一个width的属性,问题解决。
这件小事说明了发散性的思维是很重要的,如果我一味地去检查CSS或试图发现TT的css hack,可能这个问题是搞不定了。
但说来说去,到底TT为什么会用ie7的内核而不是系统上的ie8的内核,哈哈,鬼知道。
补记:写这篇日志之后的若干星期,无意中在IE的“开发人员工具”里发现了一个浏览器模式设置,骇然有IE7可选,可见WIN7不仅有IE8内核,还有IE7的。CS兄又指教说:如果系统用的是IE8的话,那么无论什么傲游360TT搜狗之类的外壳浏览器统统都是用IE7模式渲染的,所以一般来说为了省事我都在正式发布页面时給meta加上一句强制让IE8也用IE7模式来渲染……这个方法真是个好办法,学习学习!!
这几天和本部一个兄弟夏先生合作完成华师大的亚运志愿者网站。由于说好我负责ASP部分,所以拿到本部发来的页面后只是顺手用360安全浏览器看了一下,毫无疑问,页面设计得很漂亮,这充分说明我们的分工是正确的——起码对于美工来说,夏先生比我好。
没有过多考虑,匆匆忙忙开始拷代码,花了一天多的时间,期间与本部进行了n次的交流,基本完成了页面功能。并上传到了服务器。心里还一个劲地感慨:合作的力量还真是强大啊。因为之前总是一个人做整个网站,基本上都得拖几个星期,就页面的设计已经能累死人了。现在有个人帮忙写css,效果的确不错。这充分说明,独行侠的年代已经过时了。当然,剩下的事可以说不是我的事了,我可不想无聊到做上传文章之类的事。
没想到的是昨晚同是亚运网络小组的梁兄突然说网站有问题,看了一下,原来用的是腾讯的TT浏览器。这才突然想起做完整个页面后都没有在各个浏览器上做过相关测试。事实上我的电脑上并没安装TT,这是个很大的漏洞,因为腾讯的爪牙现在几乎是伸遍了中国任何一台能上网的PC,TT浏览器使用量还是相当可观的,而我之前测试页面居然一直没有留意到真是吓了一跳。忙回来下了一个安装。事实证明,页面在TT上确实是存在问题的。有这么几个div的嵌套:
<div>
<div style="float:left;">框一</div>
<div style="float:left;">框二</div>
</div>
在IE8上,呈现出来的页面是理想的:框一在框二的左边。但在TT上,框二却掉到了框一的下面。原本以为又是浏览器不兼容的问题,决定用css hack解决。Google了一番,却发现到此都说TT使用的是IE的核心,因而只要页面在IE上显示正常,在TT上也应该是正常的,所以TT没有特定的css hack可写。这真是见鬼了,因为在我的电脑上,整个页面在IE(win7的IE版本是IE8)上是很正常的,照上面的理论,TT上也应该正常才是。怀着不服气的心理检查了半天的css,发现没有任何问题,情绪无比低落。就在准备投降的时候,突然灵感光顾,顺手打开了IETester,先用IE6试验,发现整个页面几乎都是变形的,面红耳赤地赶紧关掉,幸好这些问题可以用css hack解决,算不上问题,又顺手用IE7试验了一下,瞬时气不打一处来。这个页面在ie7下的bug和TT上的错误是完全一致的。这么说来,TT使用的内核应该是ie7的内核,而不是我系统上的ie8的内核,这到底是什么原因,有待了解。但既然是ie7的内核,问题就好解决多了,起码我可以使用ie7的css hack来处理,这比起无从下手要简单N倍了。
记得韩寒有句很经典的话:灵感就像公共汽车,不来的时候一部都没有,一来的时候几部一起来。此时我突然又想起应该在TT上查看一下页面的源代码,起码能知道asp输出的html是不是有问题的。检查之后,发现了一个很重要的线索:如上所述的两个div,放的都是用asp生成的一个标题列表,这些列表是用table包围起来的,如下:
<div class="pack">
<div style="float:left;" id="div1">
<table><tr><td style="width:100%">XX的标题</td></tr></table>
</div>
<div style="float:left;" id="div2">
<table><tr><td style=""width:100%"">XX的标题</td></tr></table>
</div>
</div>
问题出在width:100%上,重复检查了一下css,发现夏兄没给div1和div2定义width,而我写asp的时候,却给td输出了一个wdith=100%的属性,所以div1就把整个pack的width占据了,div2自然只好放到了下面。明白了道理,解决起来就简单得不得了了,只要给div1和div2加一个width的属性,问题解决。
这件小事说明了发散性的思维是很重要的,如果我一味地去检查CSS或试图发现TT的css hack,可能这个问题是搞不定了。
但说来说去,到底TT为什么会用ie7的内核而不是系统上的ie8的内核,哈哈,鬼知道。
补记:写这篇日志之后的若干星期,无意中在IE的“开发人员工具”里发现了一个浏览器模式设置,骇然有IE7可选,可见WIN7不仅有IE8内核,还有IE7的。CS兄又指教说:如果系统用的是IE8的话,那么无论什么傲游360TT搜狗之类的外壳浏览器统统都是用IE7模式渲染的,所以一般来说为了省事我都在正式发布页面时給meta加上一句强制让IE8也用IE7模式来渲染……这个方法真是个好办法,学习学习!!